
Soul Zhang Lu Team Propels Real-Time Digital Human Generation Toward Long-Duration Stability with the Release of Open-Source Model SoulX-LiveAct
Recently, the AI team (Soul AI Lab) led by Soul App founder Zhang Lu released a new real-time digital human generation solution—the open-source model SoulX-LiveAct. Through systematic optimization of the autoregressive diffusion (AR Diffusion) paradigm, the model advances real-time digital human generation from merely “operational” to “reliably stable over long durations.” This progress not only addresses a critical industry challenge in long-video generation but also charts a more viable path for the practical deployment of digital human technology.
Within the existing technical ecosystem, AR diffusion has streaming generation capabilities but frequently encounters dual challenges during prolonged operation: growing GPU memory usage and declining stability. As generation duration increases, conventional KV cache mechanisms continuously accumulate historical information, causing linear growth in memory consumption and ultimately degrading output quality. SoulX-LiveAct tackles this issue with structural improvements at two levels—condition propagation and historical memory management—enabling the model to maintain stable performance even during extended sessions.

In terms of real-time performance, SoulX-LiveAct achieves 20 FPS real-time streaming inference at 512×512 resolution using only 2 H100/H200 GPUs, with an end-to-end latency of approximately 0.94 seconds. Meanwhile, per-frame computational cost is reduced to 27.2 TFLOPs/frame, effectively managing hardware resource consumption while preserving real-time capability. This performance profile provides a practical reference for cost control in production deployments.
The above performance is primarily enabled by two core mechanisms: Neighbor Forcing and ConvKV Memory. Neighbor Forcing aligns context information within the same diffusion step during the autoregressive process, keeping both the context and current predictions in a consistent noise semantic space. This reduces distributional bias introduced by cross-step propagation. Compared to conventional methods, this mechanism helps the model learn more stable temporal relationships.
In parallel, ConvKV Memory introduces a hierarchical approach to historical information: short-term memory retains high-precision information to ensure local detail and continuity, while long-term memory is compressed through lightweight convolution into fixed-length representations. This “precise + compressed” combination allows the model to preserve global consistency without unbounded memory growth. Additionally, a RoPE Reset mechanism aligns position encodings, further mitigating positional drift in long sequences.
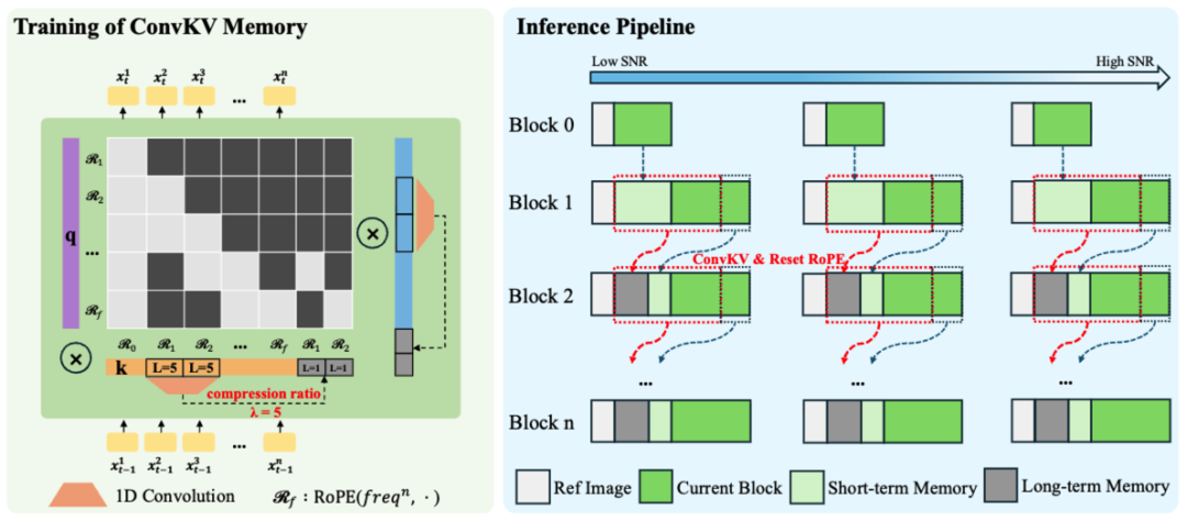
Regarding training strategy, SoulX-LiveAct emphasizes consistency with the inference process. The model incorporates memory mechanisms and context organization methods identical to those used during inference right from the training phase, enabling it to maintain stable performance even with compressed historical information. By constructing continuous chunks that simulate error accumulation and correction during extended generation, the model develops the capacity to handle instability factors inherent in long sequences.
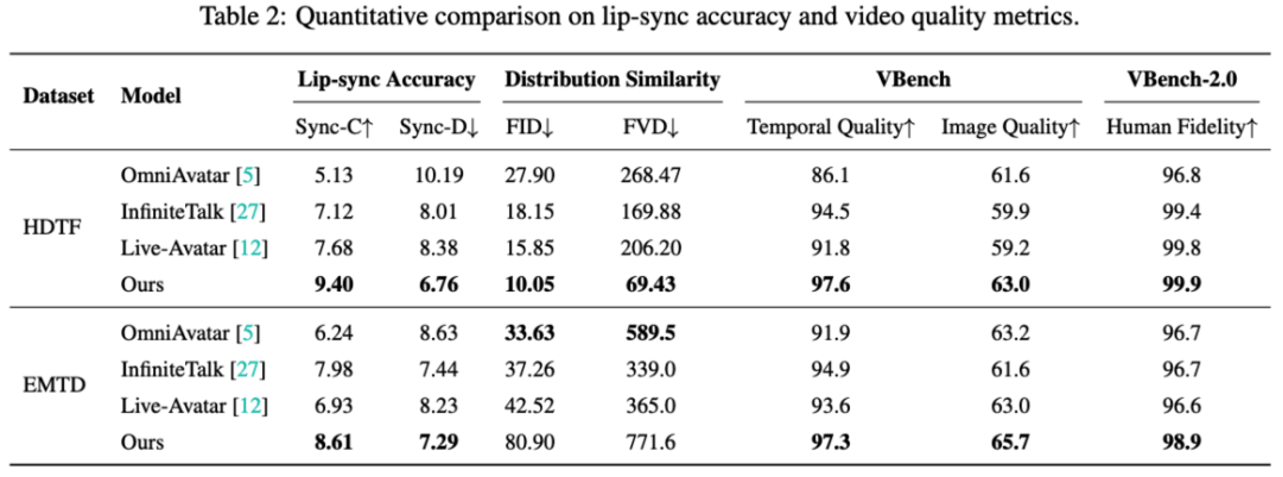
Evaluation results show that SoulX-LiveAct achieves well-balanced performance across multiple metrics. On the HDTF dataset, it scores 9.40 for Sync-C and 6.76 for Sync-D, with distribution similarity metrics of 10.05 FID and 69.43 FVD. In VBench, it reaches 97.6 for Temporal Quality and 63.0 for Image Quality, with VBench-2.0 Human Fidelity at 99.9. On the EMTD dataset, Sync-C is 8.61 and Sync-D is 7.29, with VBench Temporal Quality at 97.3, Image Quality at 65.7, and Human Fidelity at 98.9. These results demonstrate the model’s comprehensive capabilities in lip-sync accuracy, motion expression, and overall consistency.
On the application front, SoulX-LiveAct’s characteristics make it suitable for a wide range of scenarios requiring sustained online operation. For example, in digital human live streaming, AI-powered education, premium content delivery, and podcast recording, the model can support continuous, stable content output. In open-world interactive environments, where characters must maintain linguistic and motor consistency over extended periods, the model’s capabilities in full-body motion and facial expression provide the foundational support for such demanding use cases.
SoulX-LiveAct’s improvements in long-duration stability and real-time performance offer a more engineering-viable solution for real-time digital human technology. Through its continued commitment to open source, the Soul Zhang Lu team provides developers and the broader industry with diversified technical options, enabling more practical development paths across different hardware configurations and application requirements.



